
Course: Implement Apache Hadoop for Big Data


































หลักสูตรอบรม : Implement Apache Hadoop for Big Data
ระยะเวลา: 3 วัน (18 ชม.) 9.00 - 16.00 น.
ราคาอบรม/ท่าน : 11,000 บาท/ 12,500 บาท (Public Training with Online/Onsite)
กรณีเป็น In-house Training จะคำนวณราคาตามเงื่อนไขของงานอบรม
*ราคาดังกล่าวยังไม่รวมภาษีมูลค่าเพิ่ม*
Public Training หมายถึง การอบรมให้กับบุคคล/บริษัท ทั่วไป ที่มีความสนใจอบรมในวิชาเดียวกัน โดยจะมี 2 แบบ
1. อบรมแบบ Online โดย Live ผ่านโปรแกรม Zoom พร้อมทำ Workshop ร่วมกันกับวิทยากร
2. อบรมแบบ Onsite ณ ห้องอบรม ที่บริษัทจัดเตรียมไว้ พร้อมทำ Workshop ร่วมกันกับวิทยากร
หมายเหตุ: - ผู้อบรมต้องนำเครื่องส่วนตัวมาใช้อบรมด้วยตัวเอง
- วันอบรมที่ชัดเจนทางบริษัทจะแจ้งภายหลัง ตามเดือนที่ผู้อบรมแจ้งความประสงค์ไว้ (ทางบริษัทขอสงวนสิทธิ์การปรับเปลี่ยน ตามความเหมาะสม)
In-house Training หมายถึง การอบรมให้กับบริษัทของลูกค้าโดยตรง โดยใช้สถานที่ของลูกค้าที่จัดเตรียมไว้ หรือจะเป็นแบบ Online ก็ได้เช่นกัน และลูกค้าสามารถเลือกวันอบรมได้
ลงทะเบียนอบรมได้ที่
เน้นการทำ Workshop ที่ถูกออกแบบมาอย่างดีเยี่ยม, สนุกสนาน, ครบครัน เพื่อช่วยในการเรียนรู้และทำให้เกิดความเข้าใจได้อย่างง่ายดายที่สุด
#พร้อมเอกสาร lab #ทุกขั้นตอน
(ลิขสิทธิ์ โดย อ.สุรัตน์ เกษมบุญศิริ)
เนื้อหาต่างๆ มีการปรับเปลี่ยน/จัดหมวดหมู่ ใหม่ทั้งหมด เพื่อทำให้ง่ายต่อความเข้าใจ
การันตีครับ ว่า ผู้อบรมทุกคนที่จบจาก course นี้จะได้รับความรู้ทั้งภาคทฤษฏีและภาคปฏิบัติ อย่างครบถ้วน เพื่อนำไปใช้ในการทำงานจริง

วิทยากร:
อ.สุรัตน์ เกษมบุญศิริ
ผู้เชี่ยวชาญและวิทยากรที่มีประสบการณ์มากกว่า 20 ปีในวงการ
พร้อมด้วยใบรับรองจากบริษัทระดับโลกมากมาย อาทิเช่น Microsoft, CompTIA, ITIL, Cisco และอื่นๆ
หลักการและเหตุผล:
This course provides the knowledge and skills to use the tools and functions needed to work within Apache Hadoop and designed for the beginner on this product.
หลักสูตรนี้เหมาะสำหรับ:
The primary audience for this course is individuals who implement Apache Hadoop in organization for Big Data technology and prepare next step to Data Analytics.
วัตถุประสงค์ของหลักสูตร:
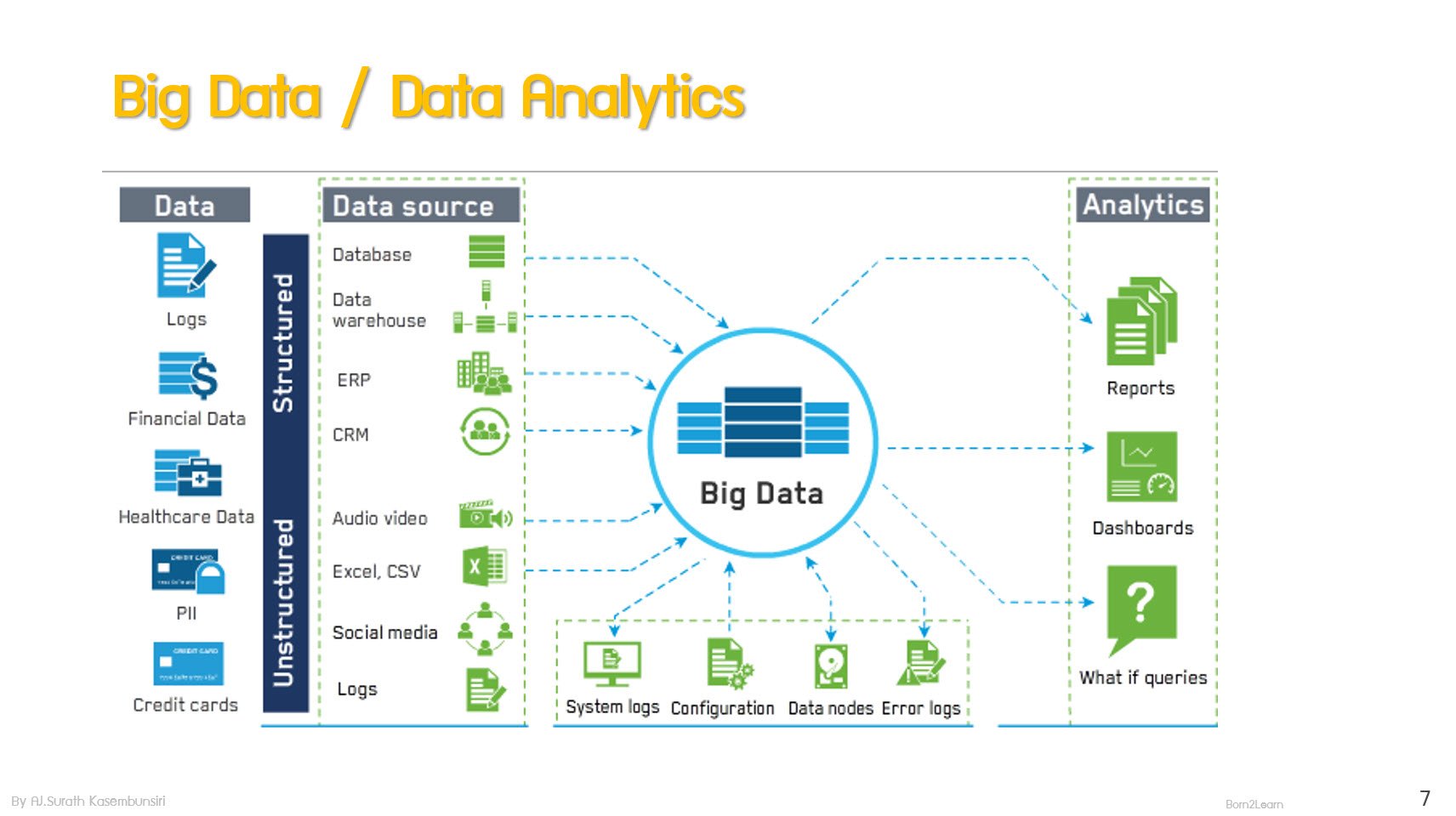
· Overview of Big Data
· Describes about ecosystem of Apache Hadoop
· How to install and configure Apache Hadoop
· Working with HDFS
· Describes concept of MapReduce
· Working with Hive, Pig and Impala
· Using Data transfer with Sqoop and Flume
ความรู้พื้นฐาน
· Working knowledge on RDBMS
เนื้อหาหลักสูตร :
Module 1: Introduction Apache Hadoop
· What is Big Data
· Big Data in The Modern World
· How to implement Big Data
· Compare Database Technology
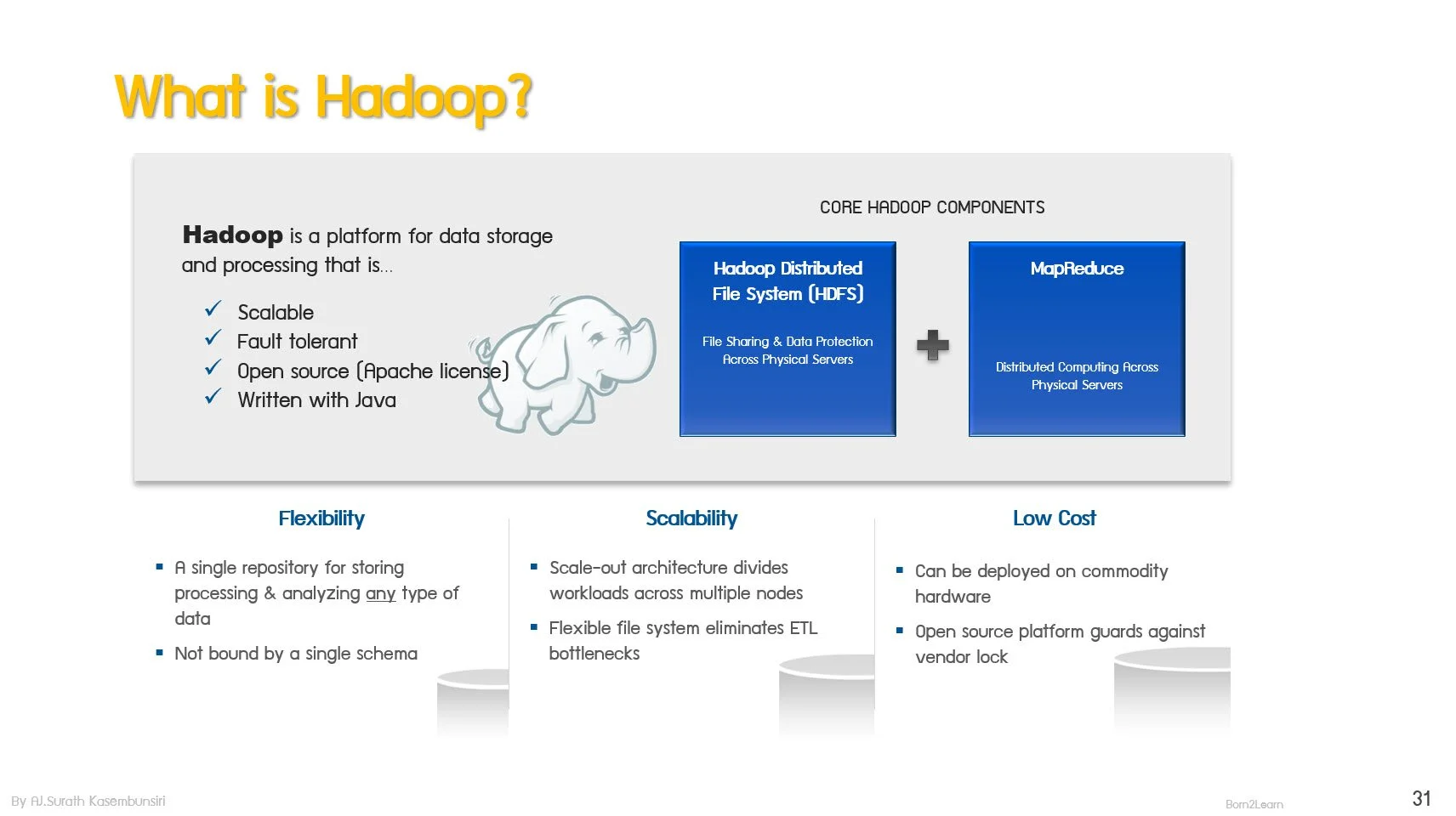
· Hadoop Overview
· Concept for implement Hadoop
· Compare Hadoop Distributions
· About Data Lake
Module 2: Hadoop Basics
· HDFS and MapReduce
· Hadoop Run Modes and Job Types
· Hadoop Software Requirement and Recommendations
· Hadoop in the Cloud
· Hadoop Installation
· About Hadoop Cluster Management
· About HUE
Module 3: Hadoop Distributed File System (HDFS)
· What’s HDFS?
· HDFS Core Concept
· HDFS Daemons (Name Node\ Data Node)
· Name Node’s Meta Data
· Function of Secondary Name Node
· HDFS HA Architecture
· HDFS File Write\Read Walkthrough
· Manage HDFS with Shell Command
· Manage HDFS with HUE
Module 4: MapReduce
· MapReduce Explained
· Map Concept
· Reduce Concept
· MapReduce Job Walkthrough
Module 5: Hive, Pig, And Impala
· Comparing Hive, Pig and Impala
· Hive Overview
· Using HiveQL
· Load Data to Hive’s Table
· Internal\ External Hive’s table
· Query data with HiveQL
· Pig Overview
· Using Pig Latin
· Databags, Tuples and Atoms
· Constructs on Pig
· Pig with HCatalog
· Impala Overview
· Using Impala-shell
· Load Data to Impala’s Table
· Query data with Impala’s command
Module 6: Data Import and Export
· About Data Analysis Workflow
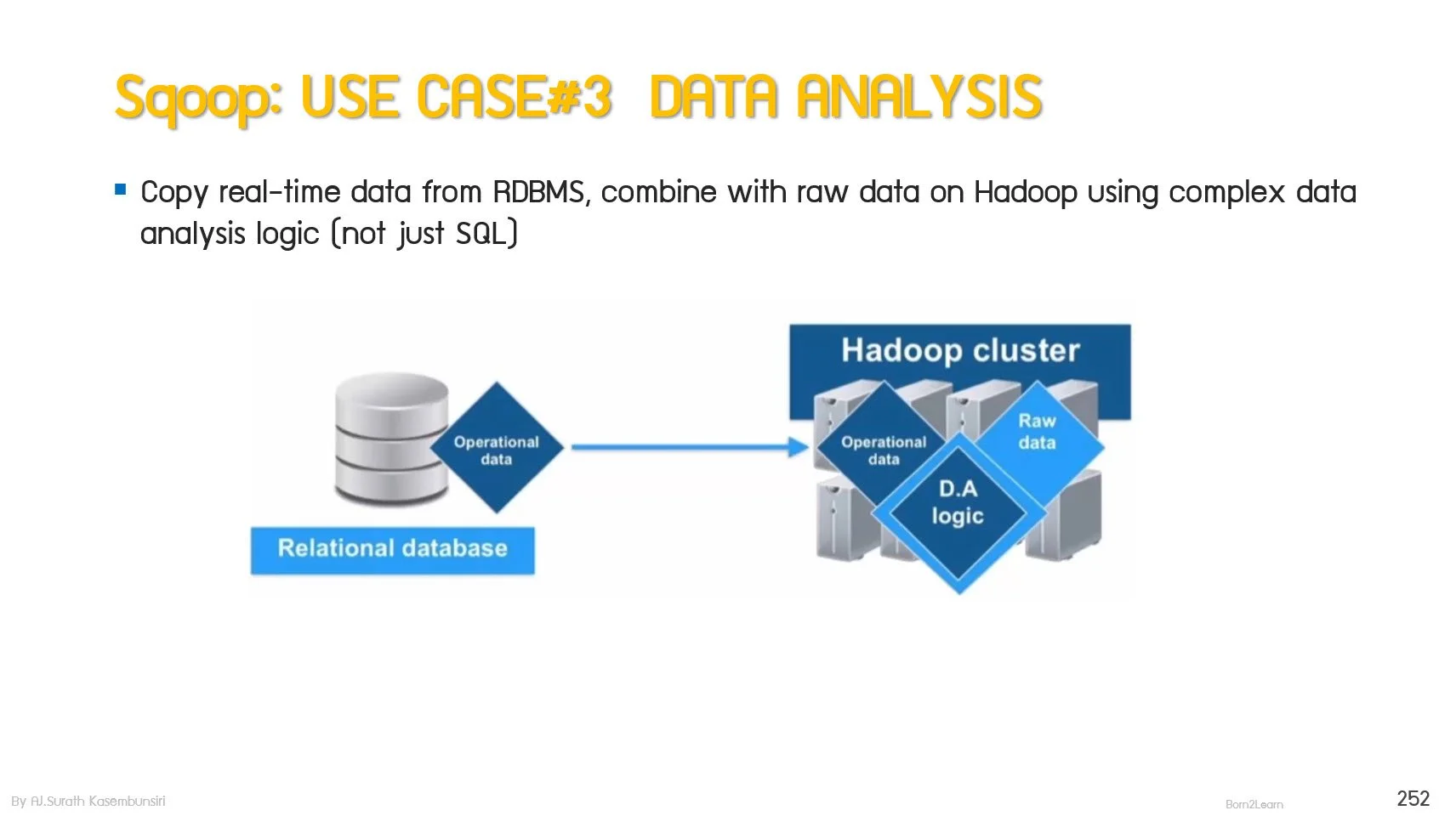
· Sqoop overview
· Sqoop use case
· How Sqoop works
· Using Sqoop’s import
· Sqoop Parallel import concept
· Sqoop’s option File
· Using Sqoop’s Hive Import
· Using Sqoop’s Incremental Import
· Using Sqoop’s Export
· Intro Oozie Workflow for import\export
· Flume Overview
· How Flume works
· Flume’s Agent and Collections
· Using Flume’s for real-time data